
As the CEO of an AI company working in the aviation industry, I spend most of my time thinking about data quality and model performance. But recently, I've been wrestling with a pattern that extends far beyond our industry, one that keeps me up at night and challenges everything I thought I knew about AI development.
It started with a random observation I shared on social media about needing more humans for AI training data. The tweet (post?) got maybe sixteen views and zero responses. But the more I've dug into this idea, the more convinced I become that we're facing a convergence of challenges that could fundamentally reshape AI development.
The Foundation is Cracking
Every successful AI system depends on quality training data, and that foundation is rapidly eroding. Most large language models have been trained on human-generated content scraped from the Internet¹, but as AI-generated content proliferates online, future models will inevitably train on a mixture of real and synthetic data.
This creates what researchers call an "autophagous" or self-consuming loop that steadily degrades model quality over successive generations². The problem isn't computational power or algorithmic sophistication. It's something much more fundamental: we're running out of quality human-generated data to train our models on.
Research from Epoch AI projects that if current trends continue, models will be trained on datasets roughly equal in size to the available stock of public human text data between 2026 and 2032³. Some projections show this could happen as early as 2025 if models are overtrained significantly. That timeline feels uncomfortably close.
The Cannibalization Problem Gets Worse
The research on "model collapse" should genuinely concern anyone building AI systems. When AI models train on AI-generated content, they gradually degenerate, producing increasingly inaccurate results with what researchers call "irreversible defects"⁴.
The mechanics are both predictable and alarming. Any errors in one model's output get baked into training its successor. New models produce their own errors that compound across generations. Scientists at Oxford documented this deterioration in a language model that, after ten generations of training on its own output, went from writing coherently about English architecture to producing gibberish about jackrabbits⁵.
Even under optimal conditions, models begin showing degradation after just five rounds of training with synthetic content⁶. The degradation follows a predictable pattern. Models suffer most at the "tails" of their data, losing exactly the kind of edge cases and unusual scenarios that make AI systems robust in real-world applications.
The Internet is Already Polluted
This isn't a theoretical future problem. Research shows that around one-third of content on crowdsourcing platforms like Amazon's Mechanical Turk already shows evidence of ChatGPT involvement⁷. The datasets we rely on for training are becoming contaminated with synthetic content right now.
Companies that scraped the web before widespread AI adoption will have significant advantages over those collecting data from the post-ChatGPT internet⁸. We're witnessing the closing of a data frontier that took decades to develop, and most people don't realize it's happening.
The Creator Economy Paradox
Here's where things get interesting and complicated. The creator economy has exploded in recent years. It's now worth approximately $104.2 billion globally with over 207 million content creators worldwide⁹. This sector is expected to double by 2027¹⁰, suggesting we should have more human-generated content than ever.
But there's a catch. The economics reveal significant challenges: only 12% of full-time creators earn more than $50,000 annually, while 46% earn less than $1,000 per year¹¹. This suggests that while more people identify as creators, sustainable production of high-quality, diverse content faces real economic constraints.
Even more concerning, 83.2% of marketers say they'll use AI tools to produce content in 2024, and bloggers report spending 30% less time creating content thanks to AI¹². The creator economy is growing, but it's increasingly reliant on AI assistance, potentially contributing to the very data pollution problem we're trying to solve.
The Demographic Reality
Now comes the part that really made me reconsider everything: human fertility rates are plummeting globally. The global fertility rate has declined from around five children per woman in 1950 to 2.2 in 2021¹³.
Recent research suggests the global fertility rate could drop below replacement level as soon as 2030¹⁴. By 2100, more than 97% of countries will have fertility rates below what's necessary to sustain population size¹⁵. This represents a fundamental demographic shift happening much faster than previous projections.
The geographic distribution matters too. Research indicates that almost 300 of the world's next thousand babies will be born in Sub-Saharan Africa, while only 52 will be born across Central, Eastern, and Western Europe combined¹⁶. This concentration could lead to less diverse global content creation as cultural and linguistic diversity becomes geographically concentrated.
Why This Connection Matters
Fewer humans doesn't just mean smaller populations. It means fewer unique perspectives, experiences, and creative works. Each person represents a distinct viewpoint shaped by individual experiences and cultural background. As fertility declines globally, we're potentially looking at reduced diversity in human thought and expression.
The timing is particularly concerning. The convergence of AI data exhaustion (projected 2026–2032) with fertility rates dropping below replacement level (projected 2030) creates a perfect storm for AI development. Just as we're running out of existing human-generated data, the production of new diverse human content may be fundamentally constrained by demographic trends.
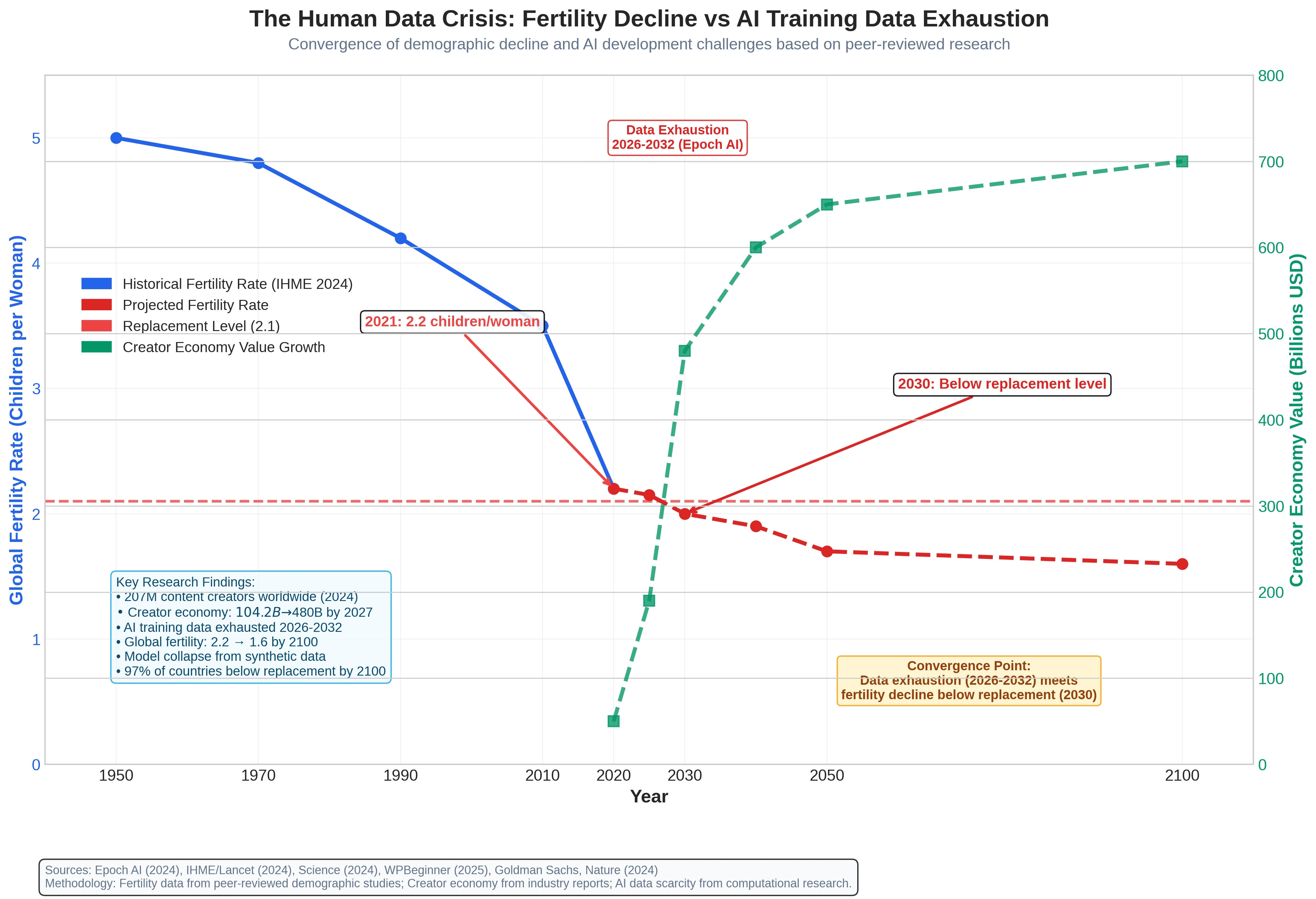
Figure 1 shows the convergence of these trends, illustrating how declining global fertility rates coincide with the projected timeline for AI training data exhaustion. While the creator economy continues to grow in dollar terms, the underlying demographic trends suggest potential long-term constraints on diverse human content generation.
This isn't about raw numbers alone. Research shows that declining fertility can lead to higher educational investments in smaller cohorts¹⁷, potentially creating more sophisticated content creators but in smaller absolute numbers. The question becomes whether higher per-capita quality can compensate for reduced total volume and diversity.
What This Means for AI Development
Human-generated content provides something AI cannot replicate: genuine variance that captures the unpredictability of real-world scenarios¹⁸. This content emerges from complex cognitive processes shaped by decades of sensory experience, emotional development, and social interaction.
The most valuable insights often come from human documentation of unusual situations, creative problem-solving approaches, and intuitive decisions. This type of content captures not just final decisions, but the reasoning processes, emotional considerations, and contextual factors that influenced those choices¹⁹. AI systems struggle to replicate this multi-layered decision-making because they lack embodied experience.
Professional domains like medicine, engineering, and emergency response contain particularly valuable human insights about navigating complex, high-stakes decisions under uncertainty. As the pool of such documentation shrinks relative to synthetic alternatives, AI systems may lose access to invaluable tacit knowledge.
Potential Solutions
The research points to several critical interventions:
Data Preservation as Strategic Asset: Companies with access to pre-synthetic human-generated data are gaining significant competitive advantages²⁰. The Data Provenance Initiative has begun auditing thousands of datasets to track content origins²¹.
Human-in-the-Loop Systems: Research consistently shows that combining synthetic data with real-world data can prevent model degradation²².
Human validation systems need robust detection mechanisms and incentive structures that reward genuine insight over AI-assisted completion.
Economic Incentives for Authentic Content: We need innovative approaches that recognize the increasing value of genuine human perspective. This could include content marketplaces, professional documentation requirements, and gamification systems that encourage authentic human contribution.
The Bigger Picture
Recent research from NYU provides some hope, showing that model collapse isn't inevitable if synthetic data accumulates alongside rather than replacing human-generated content²³. Microsoft's work with Orca-AgentInstruct demonstrates that sophisticated approaches using raw human documents as input can improve model performance²⁴.
But the challenge remains significant. The limitations could mean that "AI's ability to tackle complex problems in healthcare, climate change, and scientific research could be stifled"²⁵. The demographic transition represents "a societal shift without precedent in modern history"²⁶ that intersects with AI development in ways we're only beginning to understand.
Looking Forward
This isn't about advocating for higher birth rates or criticizing AI development. It's about recognizing that authentic human experience is becoming infrastructure-critical for AI development. Every time someone documents unique professional insights, creates original content, or shares authentic experiences, they're contributing to the quality data pool that keeps AI systems grounded in reality.
The future of AI isn't just about better chips or more sophisticated algorithms. It's about maintaining access to the rich, diverse, human-generated content that gives these systems their foundation. In a world increasingly dominated by synthetic content, authentic human experience becomes not just valuable, but essential.
As we build AI systems that will shape our future, we can't forget that their intelligence ultimately derives from ours. The quality of tomorrow's AI depends on the diversity and authenticity of today's human contributions, and the research suggests this resource is becoming increasingly scarce just when we need it most.
References
¹ IBM. (2025). What Is Model Collapse? IBM Think Topics. Available at: https://www.ibm.com/think/topics/model-collapse
² Scientific American. (2024). AI-Generated Data Can Poison Future AI Models. Available at: https://www.scientificamerican.com/article/ai-generated-data-can-poison-future-ai-models/
³ Villalobos, P., Ho, A., Sevilla, J., Besiroglu, T., Heim, L., & Hobbhahn, M. (2024). Will we run out of data? Limits of LLM scaling based on human-generated data. Epoch AI. Available at: https://epoch.ai/blog/will-we-run-out-of-data-limits-of-llm-scaling-based-on-human-generated-data
⁴ IBM. (2025). What Is Model Collapse? IBM Think Topics. Available at: https://www.ibm.com/think/topics/model-collapse
⁵ Shumailov, I., Shumaylov, Z., Zhao, Y., Gal, Y., Papernot, N., & Anderson, R. (2024). The curse of recursion: Training on generated data makes models forget. Nature, 631(8020), 755–759. Available at: https://doi.org/10.1038/s41586-024-07566-y
⁶ Futurism. (2023). When AI Is Trained With AI-Generated Data, It Starts Spouting Gibberish. Available at: https://futurism.com/the-byte/ai-trained-with-ai-generated-data-gibberish
⁷ Scientific American. (2024). AI-Generated Data Can Poison Future AI Models. Available at: https://www.scientificamerican.com/article/ai-generated-data-can-poison-future-ai-models/
⁸ TechTarget. (2024). Model collapse explained: How synthetic training data breaks AI. Available at: https://www.techtarget.com/whatis/feature/Model-collapse-explained-How-synthetic-training-data-breaks-AI
⁹ WPBeginner. (2025). 2025's Creator Economy Statistics That Will Blow You Away. Available at: https://www.wpbeginner.com/research/creator-economy-statistics-that-will-blow-you-away/
¹⁰ Uscreen. (2025). Top 10 Creator Economy Trends for 2025. Available at: https://www.uscreen.tv/blog/creator-economy-trends/
¹¹ Influencer Marketing Hub. (2024). 20 Creator Economy Statistics That Will Blow You Away in 2023. Available at: https://influencermarketinghub.com/creator-economy-stats/
¹² Uscreen. (2025). Top 10 Creator Economy Trends for 2025. Available at: https://www.uscreen.tv/blog/creator-economy-trends/
¹³ Institute for Health Metrics and Evaluation. (2024). The Lancet: Dramatic declines in global fertility rates set to transform global population patterns by 2100. Available at: https://www.healthdata.org/news-events/newsroom/news-releases/lancet-dramatic-declines-global-fertility-rates-set-transform
¹⁴ Science. (2024). Population tipping point could arrive by 2030. Available at: https://www.science.org/content/article/population-tipping-point-could-arrive-2030
¹⁵ The Lancet. (2024). Global fertility in 204 countries and territories, 1950–2021, with forecasts to 2100. Available at: https://www.thelancet.com/journals/lancet/article/PIIS0140-6736(24)00550-6/fulltext
¹⁶ McKinsey Global Institute. (2025). Dependency and depopulation? Confronting the consequences of a new demographic reality. Available at: https://www.mckinsey.com/mgi/our-research/dependency-and-depopulation-confronting-the-consequences-of-a-new-demographic-reality
¹⁷ CEPR. (2024). Confronting low fertility rates and population decline. Available at: https://cepr.org/voxeu/columns/confronting-low-fertility-rates-and-population-decline
¹⁸ IBM. (2025). What Is Model Collapse? IBM Think Topics. Available at: https://www.ibm.com/think/topics/model-collapse
¹⁹ Lily AI. (2025). AI Training Data: Why It's GIGO When Building Next Generation Frontier Firms. Available at: https://www.lily.ai/resources/blog/ai-training-data-why-its-gigo-when-building-next-generation-frontier-firms/
²⁰ TechTarget. (2024). Model collapse explained: How synthetic training data breaks AI. Available at: https://www.techtarget.com/whatis/feature/Model-collapse-explained-How-synthetic-training-data-breaks-AI
²¹ IBM. (2025). What Is Model Collapse? IBM Think Topics. Available at: https://www.ibm.com/think/topics/model-collapse
²² Gretel. (2024). Addressing Concerns of Model Collapse from Synthetic Data in AI. Available at: https://gretel.ai/blog/addressing-concerns-of-model-collapse-from-synthetic-data-in-ai
²³ NYU Center for Data Science. (2024). Overcoming the AI Data Crisis: A New Solution to Model Collapse. Available at: https://nyudatascience.medium.com/overcoming-the-ai-data-crisis-a-new-solution-to-model-collapse-ddc5b382e182
²⁴ The Stack. (2024). Synthetic data does NOT cause AI model collapse, Microsoft shows. Available at: https://www.thestack.technology/microsoft-synthetic-data-does-not-cause-ai-model-collapse-2/
²⁵ Pieces. (2024). Data Scarcity: When Will AI Hit a Wall? Available at: https://pieces.app/blog/data-scarcity-when-will-ai-hit-a-wall
²⁶ McKinsey Global Institute. (2025). Dependency and depopulation? Confronting the consequences of a new demographic reality. Available at: https://www.mckinsey.com/mgi/our-research/dependency-and-depopulation-confronting-the-consequences-of-a-new-demographic-reality
Related Posts


